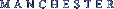

Research Projects
The Romani Morpho-Syntax (RMS) Database & Dialect Survey
- Jump to section
Project description
The RMS database project was launched in 1998 with the aim of compiling a comparative description of Romani dialects in electronic form. The principal focus is on variation in the domain of morpho-syntax, but lexical, lexico-phonetic, and some phonological features are also included. The material covered draws on published sources as well as on descriptive fieldwork carried out as part of the project. The methodology employed is typological, descriptive, and historical.
The database is currently stored in FilemakerPro 6, a user-friendly database application. It has two dimensions: Records represent individual sources on individual dialects (a dialect can have more than one record if there are several different sources). Fields are entries in response to questions. Some fields are text fields which contain examples. Others are pre-defined value lists that contain categorisations of various kinds. Fields are displayed in a number of different Layouts; these tend to correspond to the chapters in a standard grammatical description (e.g. 'word order', 'nominal derivation', 'definite and indefinite articles', 'complementation', 'lexical phonology', 'verb inflection', 'demonstratives', and many more).
The data are tagged in several ways:
- Examples can be accompanied by analytic descriptions, for instance a 'yes' or a 'no' in response to a particular question targeting a general aspect of structural variation, e.g. “is the definite article retained in this dialect?” followed by fields indicating the individual forms of the definite article, representing an historical form-to-form development.
- Functions of inherited forms are encoded, allowing the user to obtain an historical form-to-function analysis, e.g. “which function do long forms of the present conjugation serve?”, options being 'present-future', 'future', 'conditional', or 'present'.
- Function-to-form questions are included, based on state-of-the-art typological descriptions in the relevant areas; e.g. “how are negative indefinites expressed in the language?”.
- Contact influences (i.e. grammatical borrowings) are tagged for source, according to the 'depth' of contact, representing up to three layers of historical contact languages: 'current L2' – that spoken in the community alongside Romani; 'recent L2' – a second language spoken only by the older generation; and 'old L2' – a language that has had a significant impact on the dialect, but is no longer in use in the community.
- Presence of lexical vocabulary items, and the presence of specific lexical-phonological developments.
The database contains altogether over 5500 fields with information on forms, or analytical questions of this kind, covering all areas of structure, with the exception of phonetics. You can view more screenshots of the RMS-Database here. [Click image for enlarged version]
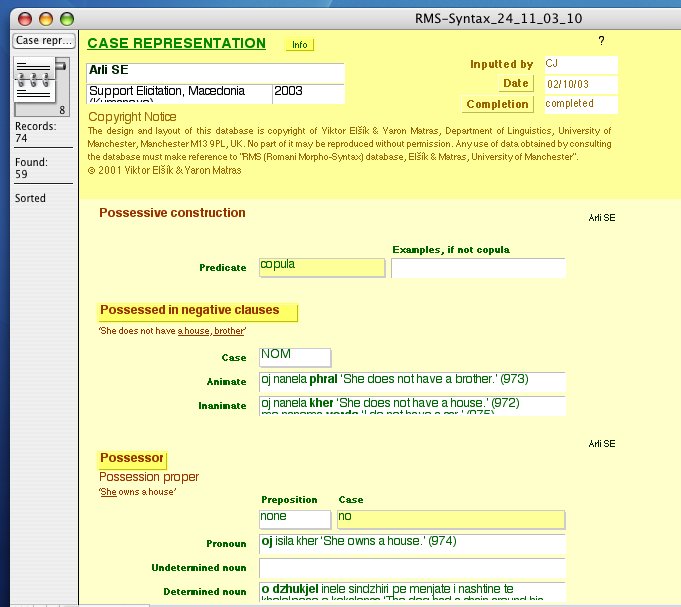
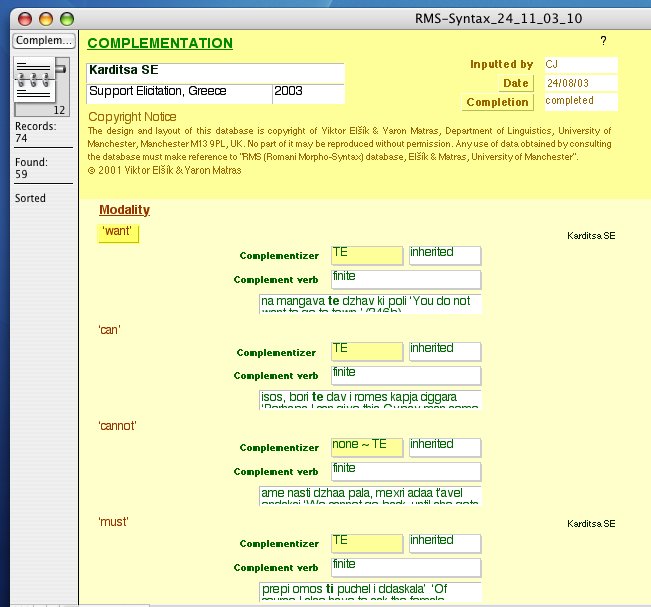
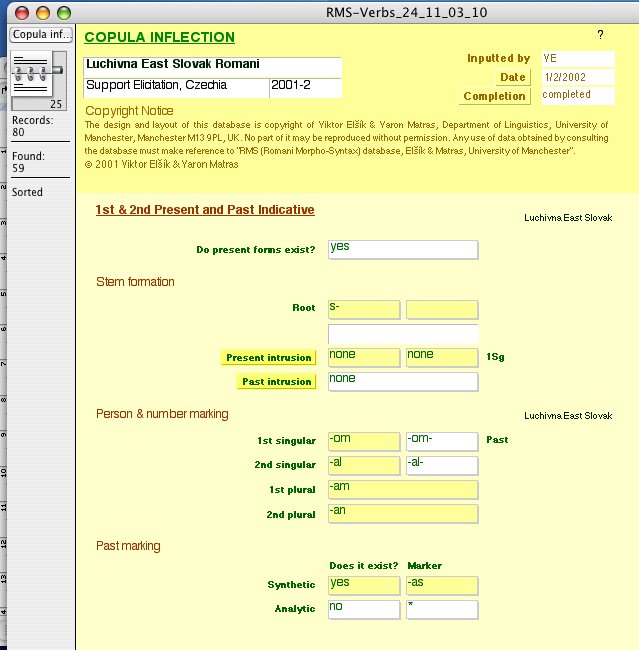
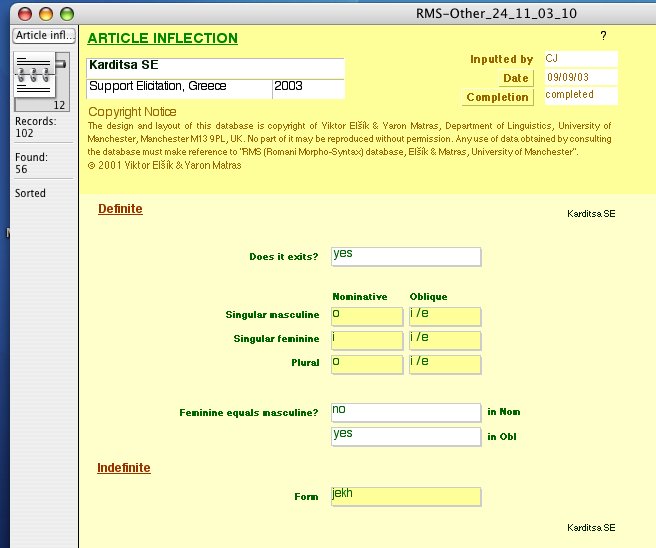
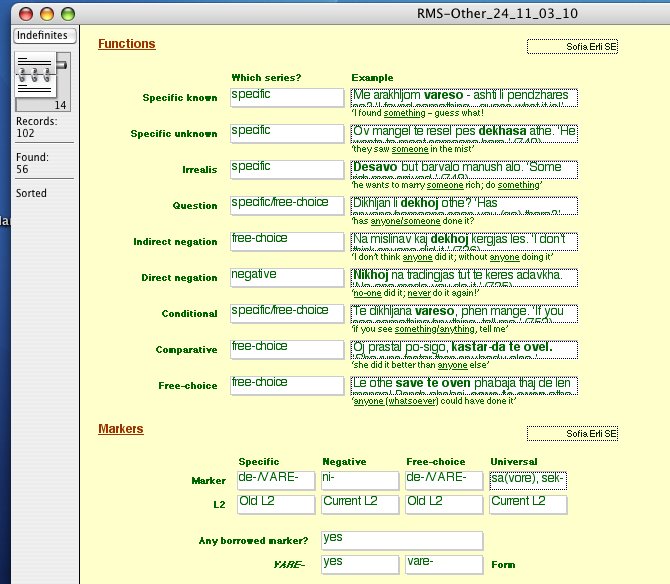
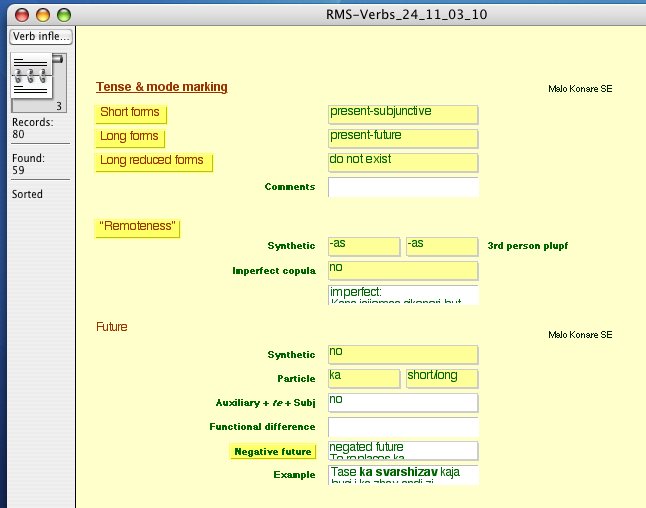
The project entered its second phase in 2001, when on the basis of the database structure an elaborate questionnaire – 'The Romani Dialectological Questionnaire' – with over 1,000 entries was designed, with the aim of extending the dataset to cover dialects that have not been thoroughly described so far. The questionnaire covers all areas of morphosyntactic variation in Romani, including conjugations of all potential verb inflection classes, and a wordlist targeting salient variation in historical lexico-phonology. The targeted categories are usually incorporated into short sentences. You can view screenshots of the RMS questionnaire here. [Click image for enlarged version]



The questionnaire, translated into numerous state languages, has since been in use across Europe to elicit translations from native speakers of Romani, often by Romani native speakers working as project fieldwork assistants. The responses are recorded and then transcribed onto a pre-formatted spreadsheet, where each numbered sentence is pre-tagged for the relevant grammatical-semantic categories that appear in it. This enables the project staff to generate sub-corpora in search of particular categories or category combinations, e.g. 'demonstratives' or 'relative clauses', thereby facilitating data entry into the database, and of course an overview of the structural features by category. You can view an excerpt of the data spreadsheet here. [Click image for enlarged version]
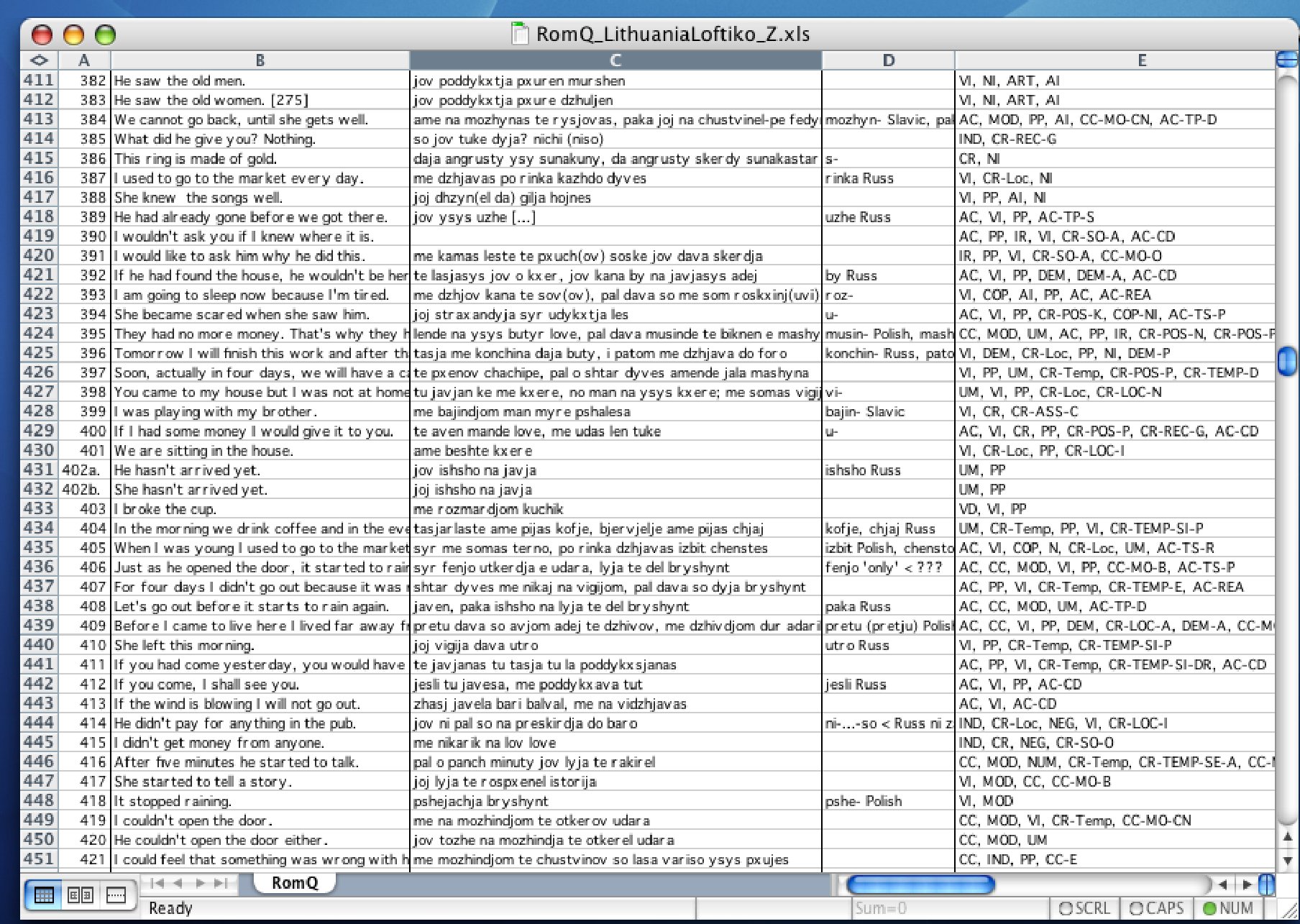
A further advantage of a uniform questionnaire is of course the fact that numerous dialects can be compared for an identical set of sample sentences.